Multimodal Generation
Text-to-Image Generation
Horse running, becoming oil painting style

An origami fox walking through the forest

A squirrel is inside a giant bright shiny crystal ball on the surface of blue ocean. There are few clouds in the sky

Robot emerging from a large column of billowing black smoke, high quality

A steaming cup of coffee with mountains in the background. Resting during road trip

Unicorn running, becoming oil painting style

Close up headshot, futuristic young woman, wild hair sly smile in front of gigantic UFO, dslr, sharp focus, dynamic composition

The moon ascends in the background, bringing nightfall around an anime girl

Text-to-Video Generation
(New!) Trained from scratch without SVD initialization
A woman in a hood walking down a dark medieval alley in the rain
Aurora Borealis Green Loop Winter Mountain Ridges Northern Lights
A bear is giving a presentation in the classroom
A steaming cup of coffee with mountains in the background. Resting during road trip
A couple dances elegantly in a luxurious hall, photorealistic
A hamster wearing virtual reality headsets is a dj in a disco
A dog driving a car on a suburban street wearing funny sunglasses
Back view on young woman dressed in a bright yellow jacket walk in outdoor forest
A really beautiful girl is smiling, best quality, super detail, 8K quality
A hamster is driving a scooter on the road very fastly
A cute mouse typing on a keyboard
A panda playing a ukulele at home
A rocket is flying through space, Slow motion, View of the space
Jack russel terrier snowboarding, GoPro shot
A beautiful scene of sunset on the water
360 camera shot of a sushi roll in a restaurant
A girl is writing something on a book, Oil painting style
A wooden barrel drifting on a river
A hamster is driving a scooter on the road very fastly
Beer pouring into glass
A boat sailing leisurely along the Seine River with the Eiffel Tower in background by Vincent van Gogh
Back view on young woman dressed in a bright yellow jacket walk in outdoor forest
A woman in a hood walking down a dark medieval alley in the rain
A beautiful scene of sunset on the water
360 camera shot of a sushi roll in a restaurant
Trained with SVD initialization
A girl is writing something on a book. Oil painting style
Two raccoons on motor bikes on a mountain road surrounded by pine trees, high definition, photo-realistic style
The sun breaks through the clouds from the heights of a skyscraper
A steam train moving on a mountainside by Vincent van Gogh
First-person view running through the woods and approaching a large beautiful cabin, highly detailed
A sailboat is sailing on a sunny day in a mountain lake
Flying through an intense battle between pirate ships in a stormy ocean
A majestic eagle soars gracefully over a breathtaking mountain range, photorealistic
The orient express driving through a fantasy landscape, animated oil on canvas
A jeep car is moving on the beach
A boat sailing leisurely along the Seine River with the Eiffel Tower in background by Vincent van Gogh
POV footage of approaching a small cottage covered in moss and many flowers, tilt shift, arc shot
Fancy skyscraper at night in flames
Waves crashing against a lone lighthouse, ominous lighting
FPV drone footage of an ancient city in autumn
FPV drone footage entering a cyberpunk city at night with many neon lights and reflective surfaces
Image-to-Video Generation
Long Video Generation
(New!) Adding Intervention Keyframes
A dog in the sun
A 360 shot of a sleek yacht sailing gracefully through the crystal-clear waters of the Caribbean
First-person view running through the woods and approaching a large beautiful cabin, highly detailed
A jeep car is moving on the beach
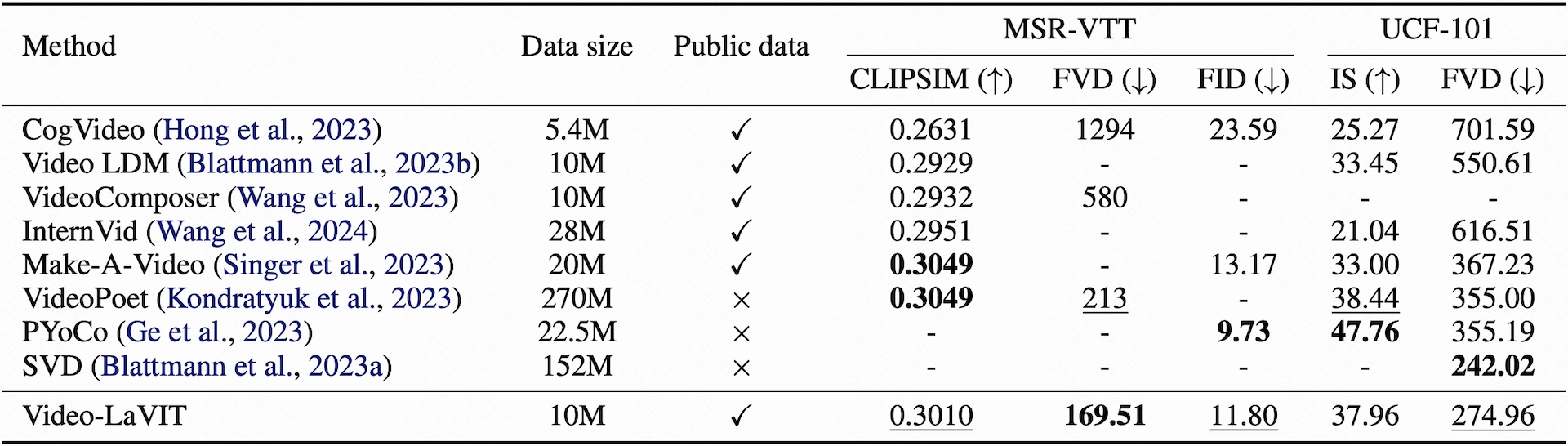
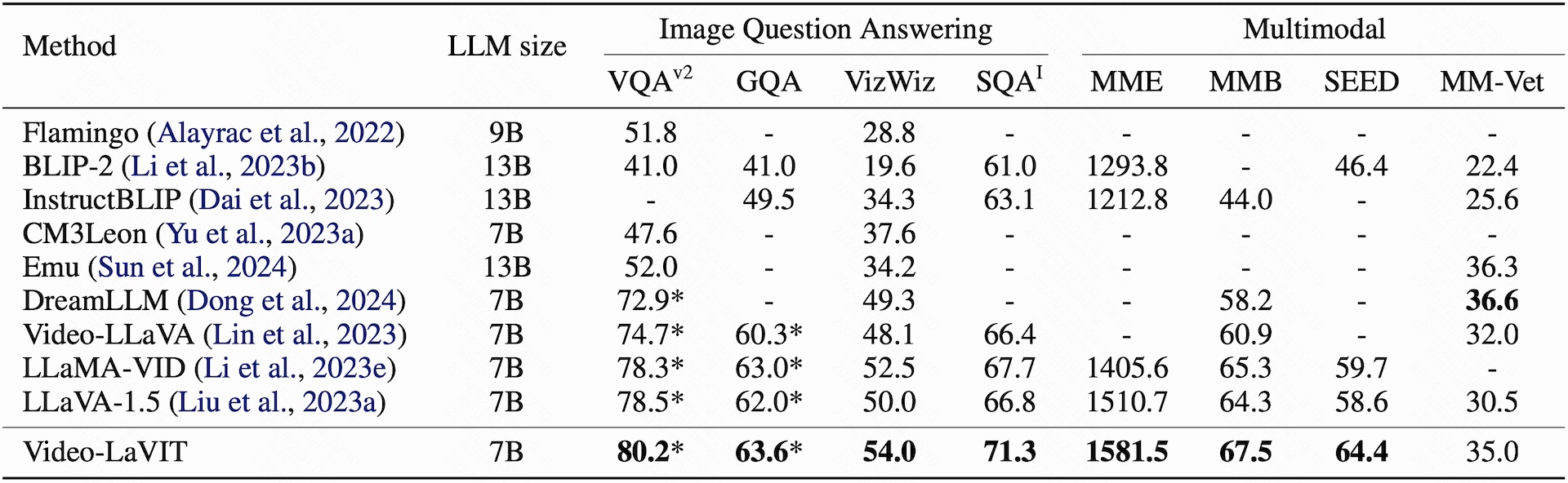
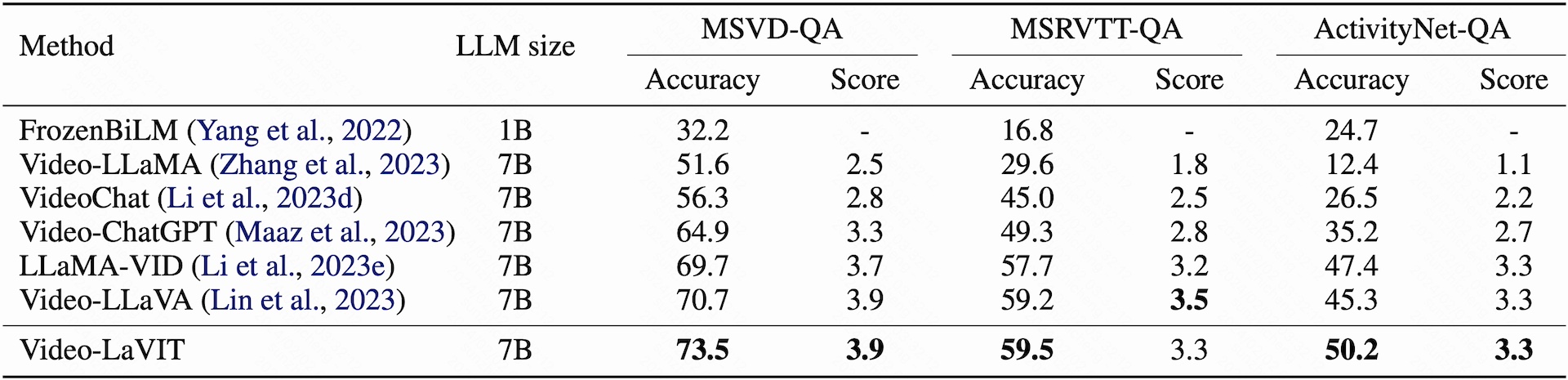
Quantitative Results